

October 25, 2022
【研究紹介】人の内面状態センシングと感情誘起への挑戦Sensing inner states and evoking pleasant emotions
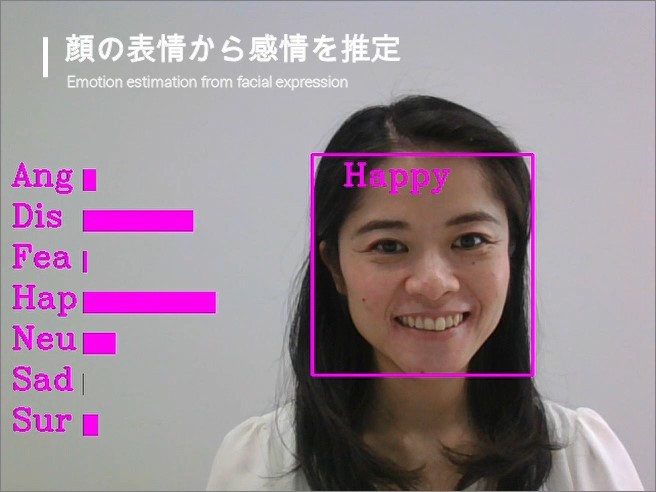
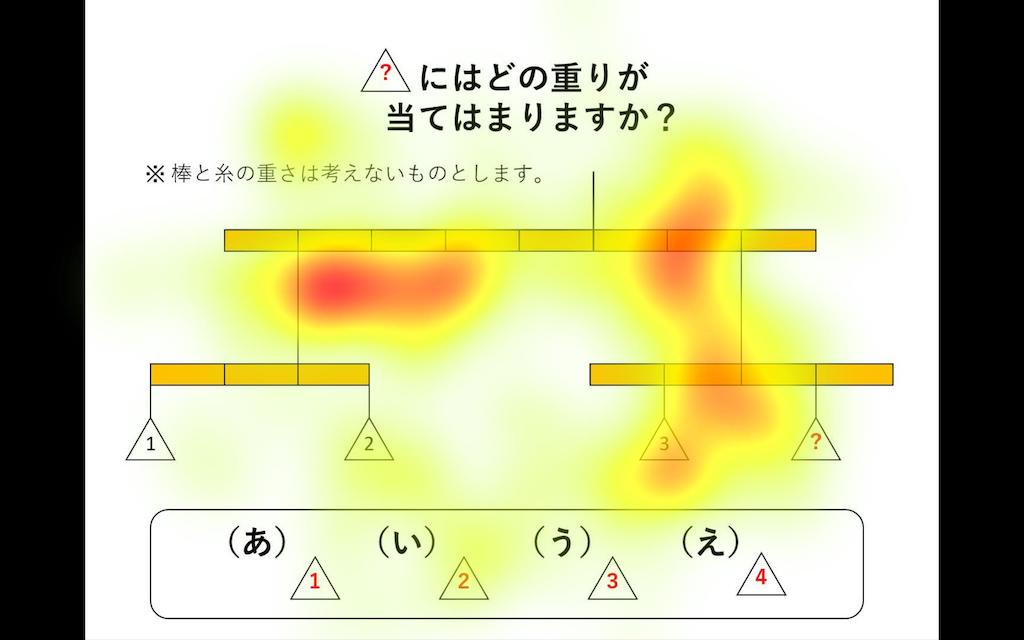

「よろこび」のような人の内面状態をセンシングする技術として、顔表情(図1, 図2)、視線(図3)、動作、音声による感情推定技術に着目しています。日常生活の中でも、教育・学びの場面を対象とした研究について、非接触での計測が可能な画像解析、音声解析による計測手法の検討を進めています。しかし、授業内容に耳を傾けている学習者においては、顔の表情変化や身体動作が小さく、発話の回数も少ないことから、内面状態を推定するための特徴抽出が困難であるという課題があります。特に、オンライン型の授業形態においては、さらに特徴の表出が乏しくなることが予測されます。そこで現在は、実際の中学校や高校で疑似的な授業動画視聴時の学習者の状態を計測し、内面状態のセンシングに繋がる特徴量の抽出に取り組んでいます(図4)。
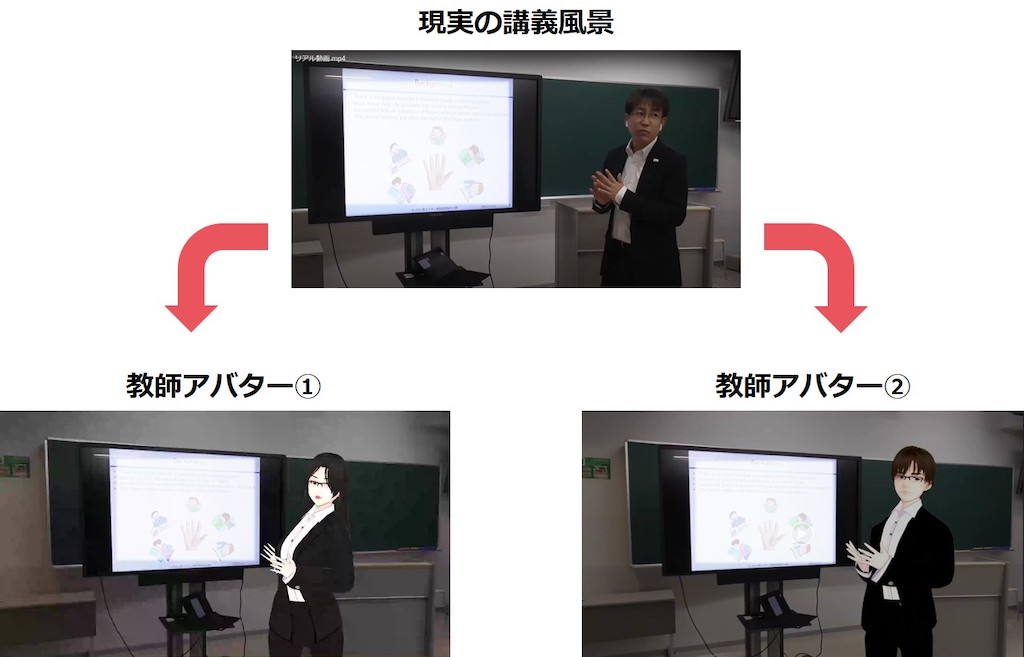
センシング技術と併せて、「よろこび」の感情を誘起するための感覚刺激の提供を考えています。将来的には、人が休息を欲する瞬間や集中力が途切れた状況を自動で検知し、適切なタイミングでの提供を目標としています。しかし、まずは本人に手動で適切なタイミングと感情を誘起する刺激を選択してもらう段階から始めます。センシングと同様に、教育・学びの場面においては、学習意欲を喚起し学習効果を向上させることを目的とした教師のマルチ・アバター化に取り組んでいます(図5)。学習者ごとに異なる学び方やその時々の内面状態に合わせて、教師の外見だけでなく身振り手振りの大きさや説明の仕方をチューニングすることを目指しています。それにより、1人の教師による授業を、各学習者に適応させた形で提供することが可能になると考えています。
現在は主に教育・学びの環境における研究を進めていますが、今後は職場環境やその他の生活環境にも対象を広げ、「よろこび」を主軸としたモチベーションの向上とそのメカニズムの解明を実現していきます。
記事:蜂須賀知理(講師)
We are focusing on emotion estimation technology based on facial expressions (Fig. 1, Fig. 2), eye gaze (Fig. 3), motion, and voice for sensing people’s inner states, such as “pleasure.” We are investigating measurement methods based on image and voice analysis that enable non-contact measurement for research on education and learning situations in our daily lives. However, it is difficult to extract features for estimating the inner state of learners who are listening to the contents of a class because there is little change in their facial expressions and body movements, and they do not speak often. Especially in online classes, it is likely that learners will exhibit even fewer features. Therefore, we are currently working on measuring the state of learners when they watch simulated class videos at actual junior and senior high schools and extracting features that will lead to sensing their inner state (Fig. 4).
Together with sensing technology, we are considering providing sensory stimuli to induce feelings of “pleasure.” In the future, our goal is to automatically detect when people lose concentration or want to rest and provide feedback stimuli at the right time. For present, however, we start by asking people manually to select the appropriate timing and emotion-evoking feedback. Like the sensing method, we are working on education and learning first in the feedback method and developing multi-avatars of teachers to stimulate learning motivation and improve learning effects (Fig. 5). We aim to tune not only the appearance of the teacher but also the size of the gestures and the method of explanation according to each learner’s different learning style and inner state. By doing so, we believe that it will be possible to provide lectures by a single teacher in a form adapted to each learner.
Currently, we are mainly conducting research in education and learning. In the future, however, we will expand the scope of study to the workplace and other living environments and realize the improvement of motivation centered on “pleasure” and elucidate its mechanism.
Text: Satori Hachisuka (Lecturer)
English proofreading: David Buist (Project senior specialist)
主担当教員Associated Faculty Members

蜂須賀 知理
- 総合分析情報学コース
HACHISUKA, Satori
- Applied computer science course